The Zotonic data model
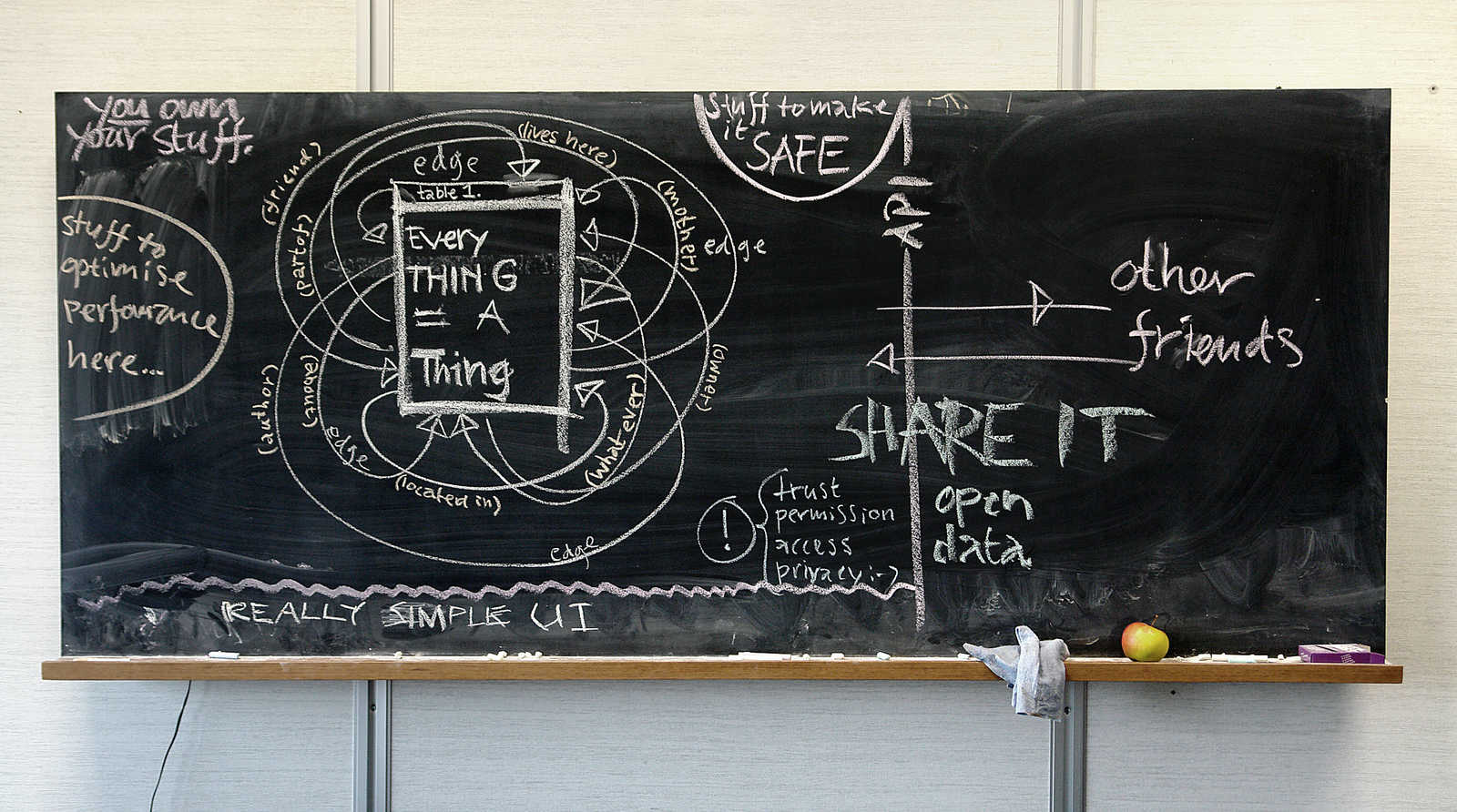
Zotonic’s data model is a pragmatic implementation of the Semantic Web: a mixture between a traditional database and a triple store.
The data model has two main concepts: the resource and the edge.
Resources, which are often called pages in the admin, are the main data unit: they have properties like title, summary, body text; and importantly, they belong to a certain category.
Edges are nothing more than connections between two resources. Each edge is labeled, with a so-called predicate.
By default, Zotonic comes with a set of categories and predicates that makes sense for typical websites.
You can extend the built-in domain model by adding your own categories and predicates.
This manual describes the data model and its related database table in depth.
The data model by example
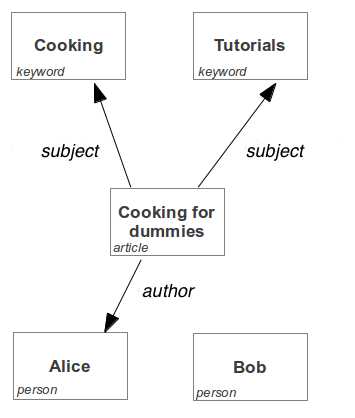
Take the example data on the right. It shows resources, connected to each other by edges. The rectangular blocks denote the resources, the arrow between them denote the edges.
It shows the domain model of a basic blog-like structure: article resources which are written by persons and articles being tagged with keywords.
The edge between Alice and cooking for dummies is labelled author: indicating that Alice wrote that article.
Note that these edges have a direction. When reasoning about edges, it is the easiest to think of them in terms of grammar: Subject - verb - object. In the case of Alice:
- Cooking for dummies is authored by Alice;
- Cooking for dummies has the keyword (subject) Cooking;
or more general:
- subject ➜ predicate ➜ object.
In Zotonic, the terms subject and object (shortened as s and o) are used in the templates, allowing you to traverse the edges between resources:
{{ m.rsc[id].o.author[1].title }}
Returns the name of the first author of the article with the given id, by traversing to the first author object edge of the given id. See the m_rsc model for more details on this.
Pages
Resources are the main building block of Zotonic’s data model. For simplicity of communication, a resource is often referred to as a page. Every resource usually has its own page on the web site, which is the HTML representation of the resource.
A resource can have multiple representations, for example application/json.
Different representations are served at different URLs. The Non-Informational Resource URI is used to negotiate the requested content-type and redirect to the best matching URI. The non-informational resource URI is usually /id/{id} where id is the numerical id of the resource. The dispatch rule is called id.
The dispatch rule for the HTML representation is called page or after the name of the category of the resource (for example article).
Resource Properties
By default, each page has the following properties.
| id | Unique number that identifies the resource and can be used for referring to the resource |
| title | Main title of the page |
| summary | Short, plain-text, summary |
| short_title | Short version of the title that is used in navigation and other places where an abbreviated title is shown |
| is_published | Only published pages are visible to the general public |
| publication_start | Date at which the page will be published |
| publication_end | Date at which the page will be unpublished |
| name | Alternative for id: used to uniquely identify the resource |
| page_path | The page’s URL on the site. Defaults to /page/{id}/{slug} where the slug is derived from the title |
| category_id | The category of the resource (see below) |
Categories
Each page belongs to exactly one category. The category a page is in determines how it is displayed.
The categories are organized in a hierarchical tree of categories and sub-categories.
For example:
- uncategorized
- text - article - news
- media - image - video - audio - document
- meta - category - predicate - keyword
Edges
An edge is a labeled connection between two resources.
The edge table defines these relations between resources. It does this by adding a directed edge from one rsc (resource) record (subject) to another (object). It also adds a reference to the predicate: the label of the edge.
In the admin, edges are represented in the “Page connections” sidebar panel, of the edit page of the subject: the resource where the edges originate. By convention, edges are said to belong to their subject. This is to simplify the access control: if you are allowed to edit the resource, you’re also allowed to edit its outgoing edges (“Page connections” in the admin), creating connections to other resources.
Predicates
Edges have a label: like in The data model by example, author is a predicate of an edge which denotes that a certain article was written by a certain person
Just like categories, these predicates are themselves also resources: allowing you to specify metadata, give them a meaningful title, et cetera.
Each predicate has a list of valid subject categories and valid object categories (stored in the predicate_category table). This is used to filter the list of predicates in the admin edit page, and also to filter the list of found potential objects when making a connection. On their edit page in the admin interface, you can edit the list of valid subject and object categories for a predicate.
Examples of predicates:
- author (from article to person)
- subject (from page to keyword)
- depiction (from any page to an image)
- relation (non defined relation between two pages)
- hasdocument (page has an attached document)